Research Note · 2017 Foundational Paper
Attention Is All You Need
NeurIPS 2017 · arXiv:1706.03762
English. original text with Korean notes
Abstract
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
1 · Introduction
Recurrent neural networks, long short-term memory[ref] and gated recurrent[ref] neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures.
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states h_t, as a function of the previous hidden state h_{t−1} and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
2 · Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU, ByteNet and ConvS2S, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations.
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as Extended Neural GPU, ByteNet and ConvS2S.
3 · Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure. Here, the encoder maps an input sequence of symbol representations (x₁,..,xₙ) to a sequence of continuous representations z = (z₁,..,zₙ). Given z, the decoder then generates an output sequence (y₁,..,yₘ) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
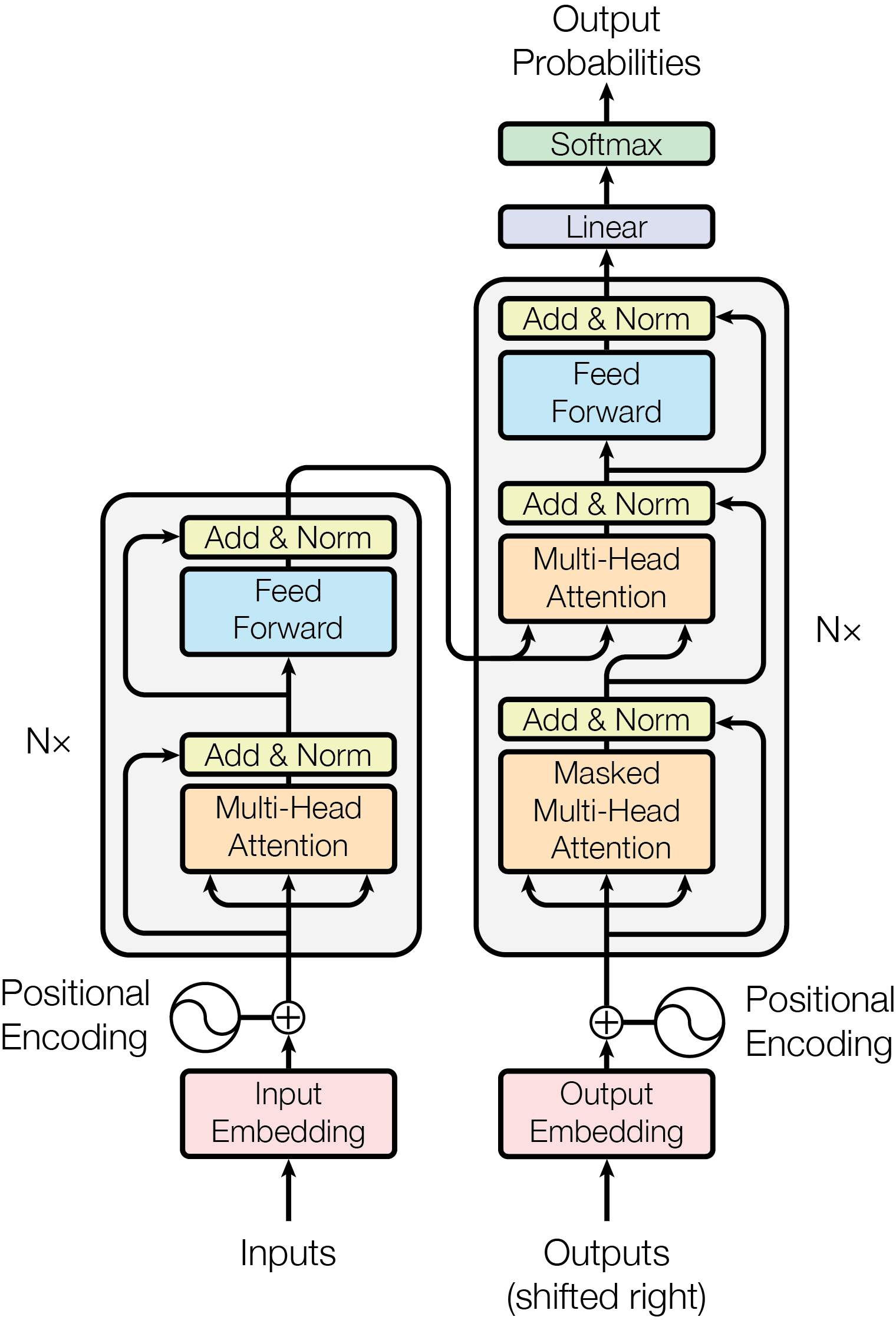
3.1 · Encoder and Decoder Stacks
Encoder
The encoder is composed of a stack of N=6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is
LayerNorm(x + Sublayer(x))
where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension d_model = 512.
Decoder
The decoder is also composed of a stack of N=6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
3.2 · Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
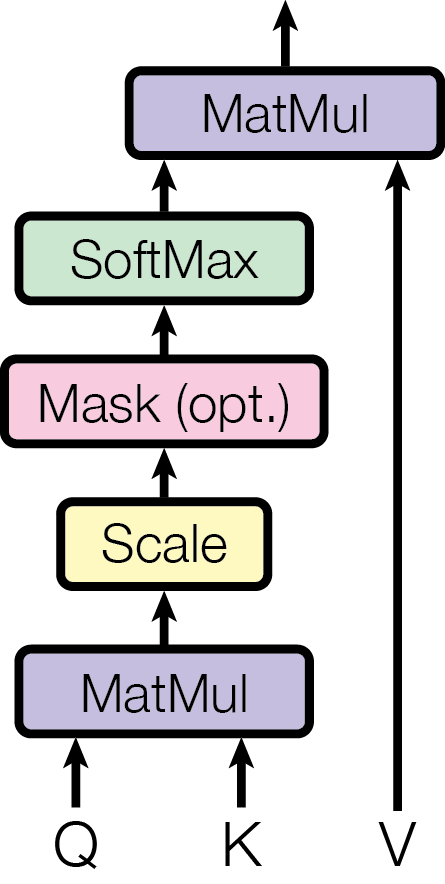 Scaled Dot-Product Attention
Scaled Dot-Product Attention
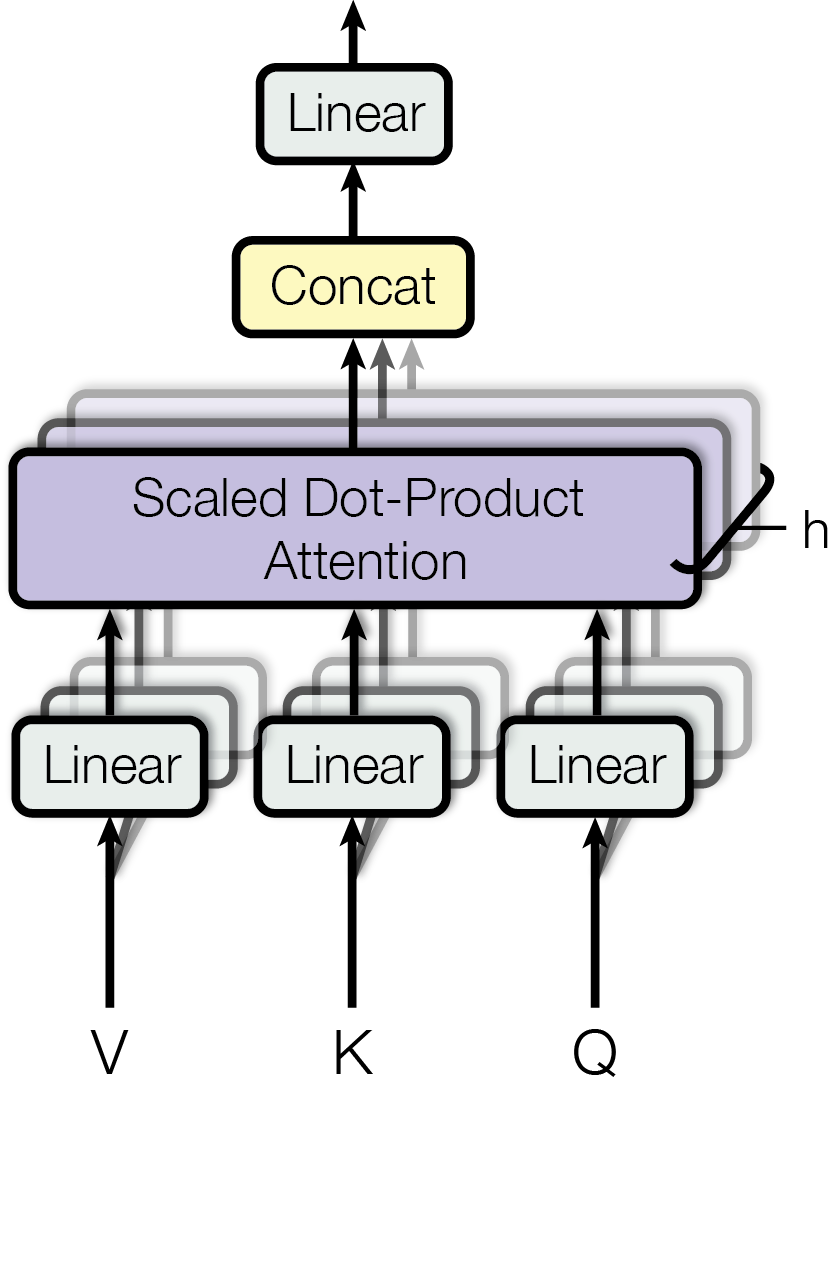 Multi-Head Attention
Multi-Head Attention
3.2.1 · Scaled Dot-Product Attention
We call our particular attention "Scaled Dot-Product Attention". The input consists of queries and keys of dimension d_k, and values of dimension d_v. We compute the dot products of the query with all keys, divide each by √d_k, and apply a softmax function to obtain the weights on the values.
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V. We compute the matrix of outputs as:
Attention(Q, K, V) = softmax(QKᵀ / √d_k) V
The two most commonly used attention functions are additive attention, and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of 1/√d_k. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
While for small values of d_k the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of d_k. We suspect that for large values of d_k, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1/√d_k.
3.2.2 · Multi-Head Attention
Instead of performing a single attention function with d_model-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to d_k, d_k and d_v dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding d_v-dimensional output values. These are concatenated and once again projected, resulting in the final values.
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
MultiHead(Q, K, V) = Concat(head₁, .., head_h) Wᴼ
where head_i = Attention(Q Wᵢᵠ, K Wᵢᴷ, V Wᵢⱽ)
Where the projections are parameter matrices Wᵢᵠ ∈ ℝ^(d_model × d_k), Wᵢᴷ ∈ ℝ^(d_model × d_k), Wᵢⱽ ∈ ℝ^(d_model × d_v) and Wᴼ ∈ ℝ^(h·d_v × d_model).
In this work we employ h=8 parallel attention layers, or heads. For each of these we use d_k = d_v = d_model/h = 64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
3.2.3 · Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models.
The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
3.3 · Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
FFN(x) = max(0, x W₁ + b₁) W₂ + b₂
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is d_model = 512, and the inner-layer has dimensionality d_ff = 2048.
3.4 · Embeddings and Softmax
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension d_model. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation. In the embedding layers, we multiply those weights by √d_model.
3.5 · Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension d_model as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed.
In this work, we use sine and cosine functions of different frequencies:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
where pos is the position and i is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from 2π to 10000·2π. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PE_{pos+k} can be represented as a linear function of PE_{pos}.
We also experimented with using learned positional embeddings instead, and found that the two versions produced nearly identical results. We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
4 · Why Self-Attention
In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations (x₁,..,xₙ) to another sequence of equal length (z₁,..,zₙ), with xᵢ, zᵢ ∈ ℝᵈ, such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.
One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies. Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.
As noted in Table 1 of the original paper, a self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires O(n) sequential operations. In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece and byte-pair representations. To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size r in the input sequence centered around the respective output position. This would increase the maximum path length to O(n/r).
A single convolutional layer with kernel width k < n does not connect all pairs of input and output positions. Doing so requires a stack of O(n/k) convolutional layers in the case of contiguous kernels, or O(log_k(n)) in the case of dilated convolutions, increasing the length of the longest paths between any two positions in the network. Convolutional layers are generally more expensive than recurrent layers, by a factor of k. Separable convolutions, however, decrease the complexity considerably, to O(k·n·d + n·d²). Even with k=n, however, the complexity of a separable convolution is equal to the combination of a self-attention layer and a point-wise feed-forward layer, the approach we take in our model.
As side benefit, self-attention could yield more interpretable models. We inspect attention distributions from our models and present and discuss examples in the appendix. Not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic and semantic structure of the sentences.
5 · Training
This section describes the training regime for our models.
5.1 · Training Data and Batching
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding, which has a shared source-target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
5.2 · Hardware and Schedule
We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models, step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
5.3 · Optimizer
We used the Adam optimizer with β₁=0.9, β₂=0.98 and ε=10⁻⁹. We varied the learning rate over the course of training, according to the formula:
lrate = d_model⁻⁰·⁵ · min(step_num⁻⁰·⁵, step_num · warmup_steps⁻¹·⁵)
This corresponds to increasing the learning rate linearly for the first warmup_steps training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps = 4000.
5.4 · Regularization
We employ three types of regularization during training:
Residual Dropout
We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of P_drop = 0.1.
Label Smoothing
During training, we employed label smoothing of value ε_ls = 0.1. This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
6 · Results
6.1 · Machine Translation
On the WMT 2014 English-to-German translation task, the big transformer model outperforms the best previously reported models (including ensembles) by more than 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4. Training took 3.5 days on 8 P100 GPUs. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models.
On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.0, outperforming all of the previously published single models, at less than 1/4 the training cost of the previous state-of-the-art model. The Transformer (big) model trained for English-to-French used dropout rate P_drop = 0.1, instead of 0.3.
For the base models, we used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals. For the big models, we averaged the last 20 checkpoints. We used beam search with a beam size of 4 and length penalty α = 0.6. These hyperparameters were chosen after experimentation on the development set. We set the maximum output length during inference to input length + 50, but terminate early when possible.
6.2 · Model Variations
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. We used beam search as described in the previous section, but no checkpoint averaging.
In Table 3 rows (A), we vary the number of attention heads and the attention key and value dimensions, keeping the amount of computation constant. While single-head attention is 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
In Table 3 rows (B), we observe that reducing the attention key size d_k hurts model quality. This suggests that determining compatibility is not easy and that a more sophisticated compatibility function than dot product may be beneficial. We further observe in rows (C) and (D) that, as expected, bigger models are better, and dropout is very helpful in avoiding over-fitting. In row (E) we replace our sinusoidal positional encoding with learned positional embeddings, and observe nearly identical results to the base model.
6.3 · English Constituency Parsing
To evaluate if the Transformer can generalize to other tasks we performed experiments on English constituency parsing. This task presents specific challenges: the output is subject to strong structural constraints and is significantly longer than the input. Furthermore, RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes.
We trained a 4-layer transformer with d_model = 1024 on the Wall Street Journal (WSJ) portion of the Penn Treebank, about 40K training sentences. We also trained it in a semi-supervised setting, using the larger high-confidence and BerkleyParser corpora with approximately 17M sentences. We used a vocabulary of 16K tokens for the WSJ only setting and a vocabulary of 32K tokens for the semi-supervised setting.
We performed only a small number of experiments to select the dropout, both attention and residual (section 5.4), learning rates and beam size on the Section 22 development set, all other parameters remained unchanged from the English-to-German base translation model. During inference, we increased the maximum output length to input length + 300. We used a beam size of 21 and α = 0.3 for both WSJ only and the semi-supervised setting.
Our results show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar. In contrast to RNN sequence-to-sequence models, the Transformer outperforms the BerkeleyParser even when training only on the WSJ training set of 40K sentences.
7 · Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
The code we used to train and evaluate our models is available at github.com/tensorflow/tensor2tensor.
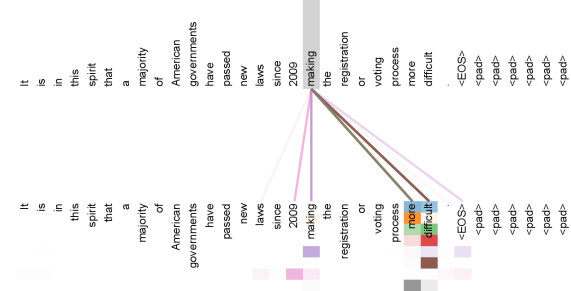
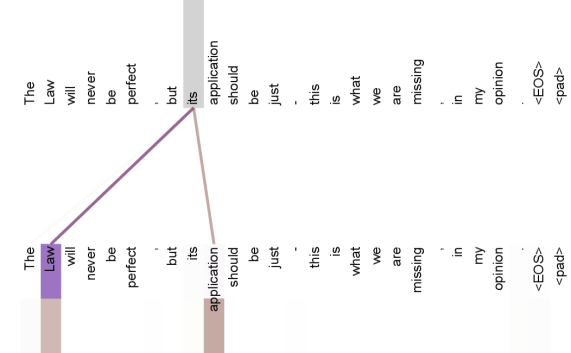
Attention Visualizations
The following figures, from the appendix of the original paper, show attention distributions learned by the encoder's self-attention heads. They illustrate that individual heads learn distinct patterns related to syntactic and semantic structure.



한국어 . 쉬운 풀이
한 줄 요약
2017년에 구글의 연구자 8명이 새로운 종류의 똑똑한 컴퓨터 프로그램을 만들었어요. 이름은 Transformer. 핵심 아이디어는 "Attention만 있으면 충분하다"는 것. 지금 우리가 쓰는 ChatGPT, Claude, Gemini 같은 거의 모든 인공지능이 이 아이디어에서 시작됐어요.
왜 새로 만들었나?
컴퓨터한테 "영어를 한국어로 바꿔봐" 같은 일을 시키려면, 먼저 컴퓨터한테 영어와 한국어를 가르쳐야 해요.
옛날 방식은 이랬어요. 컴퓨터가 문장을 읽을 때 한 단어씩 차례차례 읽었어요. 우리가 책 읽는 것처럼요.
두 가지 문제가 있었어요.
1) 너무 느려요. "I love you"를 처리할 때, 컴퓨터는 "I" 다음에 "love" 다음에 "you" 이렇게 순서대로만 읽을 수 있었어요. 컴퓨터는 동시에 여러 일을 할 수 있는 능력이 있는데, 이 방식은 그 능력을 못 살렸어요.
2) 멀리 떨어진 단어 사이 관계를 잘 못 봐요. "어제 John이 펫샵에서 사 온 고양이가 그 물고기를 먹었다." 같은 긴 문장에서 "고양이"와 "먹었다"가 멀리 떨어져 있어요. 옛날 방식은 중간 단어들을 거치면서 앞 단어를 잊어버리기 쉬웠어요.
연구자들의 아이디어: "한 단어씩 차례대로 읽지 말고, 모든 단어를 한 번에 보면 어떨까?"
이걸 가능하게 한 방법이 바로 Attention(주의) 메커니즘이에요.
Attention이 뭔가요?
한 단어를 이해할 때, 같은 문장 안에 있는 어떤 단어들을 같이 봐야 하는지 컴퓨터가 스스로 찾는 능력이에요.
이걸 문장 안의 모든 단어에 대해 동시에 해요. 한 번에 다 봐요. 그래서 빨라요.
어떻게 작동하는지 차근차근
전체 모양은 이렇게 생겼어요 (논문의 Figure 1).
1단계: 단어를 숫자로 바꾸기
컴퓨터는 "고양이"라는 글자를 그대로 다룰 수 없어요. 그래서 숫자 묶음으로 바꿔요.
"고양이" 를 512개의 숫자로 바꿈
예: [0.3, 0.7, 0.1, 0.5, -0.2, ...]
비슷한 의미의 단어들은 비슷한 숫자가 돼요. "고양이"와 "강아지"는 가까운 숫자, "고양이"와 "자동차"는 멀리 떨어진 숫자가 돼요.
2단계: 단어에 자리 번호 붙이기
"고양이가 쥐를 물었다"와 "쥐가 고양이를 물었다"는 단어들은 같지만 뜻이 정반대예요. 순서가 중요해요.
옛날 방식은 단어를 순서대로 읽으니까 순서를 자연스럽게 알았어요. 하지만 새 방식은 모든 단어를 한 번에 보니까 순서를 따로 알려줘야 해요.
해결책: 각 단어에 "너는 1번 자리야", "너는 2번 자리야" 라고 번호를 붙여줘요. 그러면 컴퓨터가 순서를 알 수 있어요.
3단계: Attention 계산 (도서관 이야기)
이게 가장 중요한 부분인데, 도서관 비유로 설명할게요.
Attention도 똑같이 작동해요.
· 어린이의 질문 = 한 단어가 묻는 것 (Query라고 불러요)
· 책 제목들 = 다른 단어들의 인식표 (Key라고 불러요)
· 책 내용들 = 다른 단어들의 실제 의미 (Value라고 불러요)
질문(Query)이 가장 잘 맞는 제목(Key)들을 찾고, 그 책들의 내용(Value)을 합쳐서 답을 만들어요. 이걸 모든 단어가 동시에 해요.
Attention 한 번
여러 개 묶은 것
4단계: 여러 명이 같이 보기
한 가지 방식으로만 보면 놓치는 게 있어요. 그래서 8명의 다른 시각으로 같은 문장을 동시에 봐요. 이걸 Multi-Head Attention이라고 해요.
5단계: 같은 일을 여러 번 반복
위의 1~4단계를 한 번 하면 한 층이에요. 이걸 6번 쌓아요.
· 첫 번째 층: 단어 하나하나 이해
· 중간 층들: 단어들이 모인 부분 이해
· 마지막 층: 문장 전체 의미 이해
책을 한 번 읽었을 때보다 여러 번 읽으면 더 잘 이해되는 거랑 비슷해요.
전체 구조는 두 부분이에요.
· 왼쪽 (인코더): 입력 문장 (예: 영어)을 이해해요. 6층.
· 오른쪽 (디코더): 그 이해를 바탕으로 출력 (예: 한국어)을 한 단어씩 만들어요. 6층.
두 부분도 서로 Attention으로 연결돼 있어요.
학습은 어떻게 시켰나요?
컴퓨터한테 가르치려면 많은 예시가 필요해요.
· 영어를 독일어로: 약 450만 쌍의 문장
· 영어를 프랑스어로: 약 3,600만 쌍의 문장
강력한 컴퓨터 8대를 함께 써서 학습시켰어요.
· 작은 모델: 12시간
· 큰 모델: 3.5일
옛날 방식으로는 며칠에서 몇 주 걸렸는데, 이건 훨씬 빨라요.
얼마나 잘 했나요?
번역 점수를 매기는 방법(BLEU 점수, 100점 만점, 사람 번역과 얼마나 닮았는지 평가)으로 측정했어요.
옛날 최고 Transformer
영어 → 독일어 약 26점 28.4점 (+2.4점)
영어 → 프랑스어 약 40점 41.0점 (+1.0점)
점수도 더 높고, 학습 시간은 1/4로 짧아졌어요. 더 잘하면서 더 빨라요.
그래서 지금은 어떻게 됐나요?
2017년에 이 논문이 나온 뒤로 AI 세상이 완전히 바뀌었어요.
지금 우리가 쓰는 거의 모든 AI가 Transformer를 기반으로 만들어졌어요.
· ChatGPT (OpenAI)
· Claude (Anthropic, 이 글을 만든 회사)
· Gemini (Google)
· Llama (Meta)
· BERT (구글 검색에 들어가 있어요)
텍스트만이 아니라 다른 분야에도 퍼졌어요.
· 이미지 인식과 생성 (Vision Transformer)
· 음성 인식 (Whisper)
· 영상 생성 (Sora)
저자들이 논문 마지막에 "이미지, 소리, 영상에도 써보고 싶다"고 적었는데, 6년 안에 정말 다 됐어요.
부록: Attention이 실제로 뭘 보는지
학습이 끝난 모델의 Attention 헤드(8명의 선생님 중 한 명)가 실제로 어떤 단어 관계를 보고 있는지 그림으로 표현한 것들이에요. 헤드마다 서로 다른 패턴을 학습한 게 보여요.